Phụ lục này mô tả bối cảnh và chi tiết tính toán cho việc chuyển giao thông tin từ một trạm có chuỗi số liệu dài ở gần sang trạm cần phân tích nhưng có chuỗi số liệu tương đối ngắn hơn. Việc chuyển giao dựa trên tương quan quan sát được giữa logarit cơ số 10 của chuỗi giá trị cực đại hàng năm tại hai trạm. Đây là một phương pháp hữu ích để truyền thông tin từ trạm có chuỗi dài sang trạm cần phân tích, đồng thời vẫn tuân thủ tiêu chí “lũ nhỏ có thể ảnh hưởng” (PILF) và cân nhắc thông tin tương đối do dữ liệu lịch sử và ước lượng độ lệch vùng (regional skewness) cung cấp. Một ví dụ được đưa ra để minh họa phương pháp này.
(nd: regional skewness)
Regional skewness (ký hiệu thường dùng: γR\gamma_R) là độ lệch vùng—tức ước lượng hệ số độ lệch (skewness) của \({log}_{10}\) chuỗi đỉnh lũ năm, được suy ra từ nhiều trạm trong cùng một vùng thủy văn “đồng nhất”.
- Nó không thứ nguyên và đại diện cho xu thế lệch chung của cả vùng (ổn định hơn ước lượng tại một trạm riêng lẻ khi chuỗi ngắn).
- Trong Bulletin 17C, \(\gamma_R\) được kết hợp với độ lệch tại trạm \(\hat{\gamma}\) để tạo độ lệch trọng số dùng vẽ đường tần suất lũ:
$$\gamma_w =\frac{\hat{\gamma}/\mathrm{MSE}(\hat{\gamma})+\gamma_R/\mathrm{MSE}(\gamma_R)} {1/\mathrm{MSE}(\hat{\gamma})+1/\mathrm{MSE}(\gamma_R)}.$$
Ví dụ nhanh: nếu \(\hat{\gamma}=0.20,\ \mathrm{MSE}(\hat{\gamma})=0.30,\ \gamma_R=0.55,\ \mathrm{MSE}(\gamma_R)=0.10\) thì \(\gamma_w = 0.4625\).
Về mặt hình thức, phương pháp dựa trên tương quan chéo giữa các đỉnh lũ tại trạm chuỗi ngắn và trạm chuỗi dài được gọi là bổ sung chuỗi số liệu (record augmentation). Tuy nhiên, vì thuật toán Bulletin 17C sử dụng ngưỡng PILF để giới hạn phân tích tần suất đối với các trận lũ lớn hơn ngưỡng PILF, nên một quy trình bổ sung chuỗi số liệu bỏ qua giới hạn này sẽ là không phù hợp. Thông tin bổ sung thu được từ phân tích bổ sung chuỗi được thể hiện như một phần mở rộng của chuỗi lũ ban đầu. Độ dài bổ sung của chuỗi được chọn sao cho xấp xỉ với “độ dài chuỗi hiệu dụng” của phần thông tin bổ sung cho phương sai được xây dựng phục vụ phân tích tần suất lũ tại trạm chuỗi ngắn. Ngưỡng PILF sau đó có thể được áp dụng cho chuỗi đã mở rộng này để đảm bảo phân tích đồng nhất các đỉnh lũ lớn hơn ngưỡng đó.
Việc bổ sung chuỗi số liệu là hấp dẫn khi đáp ứng hai điều kiện. Thứ nhất, chuỗi số liệu tại trạm quan tâm tương đối ngắn. Thứ hai, có một trạm chuỗi dài gần đó mà chuỗi lũ của nó tương quan cao với chuỗi lũ tại trạm chuỗi ngắn. Khi đó, chuỗi dài có thể được dùng để kéo dài hiệu quả chuỗi tại trạm chuỗi ngắn bằng cách sử dụng tương quan chéo giữa lũ tại hai trạm. Khuyến nghị là chỉ nên bổ sung chuỗi khi hệ số tương quan chéo \(\rho > 0.80\) và trạm chuỗi ngắn có thời gian ghi nhận dưới 20 năm. Việc bổ sung chuỗi vẫn có thể hữu ích khi trạm chuỗi ngắn có thời gian ghi nhận vượt quá 20 năm. Trong mọi trường hợp, tối thiểu cần có 10 năm dữ liệu trùng thời gian tại cả hai trạm.
Matalas và Jacobs (1964) và Vogel và Stedinger (1985) đã thảo luận các quy trình bổ sung chuỗi, đồng thời đưa ra các tiêu chí phức tạp hơn cho các trường hợp khi tương quan chéo giữa hai chuỗi lũ và thời gian trùng nhau của số liệu không đủ để quy trình mang lại lợi ích về giá trị trung bình và phương sai tại trạm chuỗi ngắn. Tương quan chéo càng lớn thì hiệu quả càng cao.
1. Bổ sung chuỗi để ước lượng trung bình (Mean) và phương sai (Variance)
Matalas và Jacobs (1964) đã phát triển một cách tiếp cận để thu được các ước lượng không chệch (unbiased) của trung bình và phương sai của chuỗi thời gian được kéo dài (chuỗi quan trắc cộng với phần chuỗi mở rộng) dựa trên hồi quy bình phương tối thiểu thông thường (OLS). Cách tiếp cận này là nền tảng của phương pháp “So sánh hai trạm” được mô tả trong Bulletin 17B (IACWD, 1982, phụ lục 7). Dùng phương pháp moment được khuyến nghị trong Bulletin 17B, có thể tính các ước lượng được cải thiện của trung bình và phương sai (độ lệch chuẩn) dựa trên thủ tục Matalas–Jacobs rồi đưa chúng vào các phép tính. Moran (1974) đã xem xét việc dùng nhiều hơn một biến giải thích—là mở rộng tiềm năng hữu ích của khái niệm này.
(nd: ước lượng không chệch)
Ước lượng không chệch (unbiased estimator) là một ước lượng \(\hat{\theta}\) của tham số \(\theta\) thỏa: \(\mathrm{E}[\hat{\theta}] = \theta\).
Nói cách khác, kỳ vọng của ước lượng bằng đúng giá trị thật — sai số trung bình dài hạn bằng 0 (không có “chệch”). Lưu ý: điều này không đảm bảo một mẫu cụ thể sẽ trúng \(\theta\); nó chỉ đúng trung bình qua nhiều mẫu.
- Độ chệch (bias): \(\mathrm{Bias}(\hat{\theta})=\mathrm{E}[\hat{\theta}]-\theta\). Không chệch khi bias = 0.
- MSE: \(\mathrm{MSE}(\hat{\theta})=\mathrm{Var}(\hat{\theta})+\mathrm{Bias}(\hat{\theta})^2\). Trong số các ước lượng không chệch, thường chọn cái có phương sai nhỏ nhất (MVUE).
Ví dụ quen thuộc
- Trung bình mẫu \(\bar{x}\) là ước lượng không chệch của trung bình tổng thể \(\mu\).
- Tỷ lệ mẫu \(\hat{p}=x/n\) là ước lượng không chệch của p (Bernoulli).
- Phương sai mẫu với hệ số Bessel: \(\frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})^2\) là không chệch cho \(\sigma^2\); còn dùng 1/n thì bị chệch thấp.
Trong bối cảnh Bulletin 17C, các thủ tục “record augmentation” được thiết kế để cho ước lượng không chệch của trung bình và phương sai khi kéo dài chuỗi bằng tương quan với trạm lân cận.
Do Bulletin 17C đưa vào tiêu chí PILF với EMA, tích hợp độ lệch vùng (regional skewness), và có thể cả thông tin lịch sử cùng các dữ liệu khác, nên việc tiếp nhận thông tin do bổ sung chuỗi cung cấp không còn đơn giản. Điều đó sẽ được thực hiện bằng Systematic record mở rộng đại diện cho phần thông tin bổ sung thu được từ tương quan với trạm có chuỗi dài. Systematic record mở rộng này được đưa vào tính toán EMA, và sau đó chịu các tiêu chí PILF.
Gọi logarit cơ số 10 của lũ tại trạm ngắn cần phân tích là \(y = \log_{10}(Q_y)\) với các giá trị được ký hiệu là \(y_i\), và logarit của lũ tại trạm dài là \(x = \log_{10}(Q_x)\) với các giá trị được ký hiệu là \(x_i\).
Giả sử \(n_1\) là độ dài chuỗi tại trạm ngắn, khi đó chuỗi sẽ là \(y_i, \ i = 1, \ldots, n_1\). Gọi \(n_2\) là số năm bổ sung của chuỗi tại trạm x, khi đó chuỗi x sẽ có dạng \(x_i, \ i = 1, \ldots, (n_1 + n_2)\).
Để thuận tiện, trình bày giả sử rằng \(n_1\) giá trị quan trắc đồng thời giữa hai trạm y và x tương ứng với \(n_1\) quan trắc đầu tiên. Điều này không bắt buộc phải đúng, và các giá trị đồng thời cũng không cần liên tiếp nhau. Chuỗi x ở đây nên được lấy từ một trạm có ý nghĩa thủy văn, với điều kiện khí hậu và đặc điểm lưu vực tương tự.
Các định nghĩa được sử dụng trong phần trình bày này bao gồm các giá trị trung bình mẫu và phương sai mẫu sau:
$$\bar{y}_1 = \frac{1}{n_1} \sum_{i=1}^{n_1} y_i \tag{8–1}$$
$$\bar{x}_1 = \frac{1}{n_1} \sum_{i=1}^{n_1} x_i \tag{8–2}$$
$$\bar{x}_2 = \frac{1}{n_2} \sum_{i=n_1+1}^{n_1+n_2} x_i \tag{8–3}$$
$$s^2_{y_1} = \frac{1}{n_1-1} \sum_{i=1}^{n_1} (y_i – \bar{y}_1)^2 \tag{8–4}$$
$$s^2_{x_1} = \frac{1}{n_1-1} \sum_{i=1}^{n_1} (x_i – \bar{x}_1)^2 \tag{8–5}$$
và
$$s^2_{x_2} = \frac{1}{n_2-1} \sum_{i=n_1+1}^{n_1+n_2} (x_i – \bar{x}_2)^2 \tag{8–6}$$
Với các định nghĩa trên, các ước lượng Matalas–Jacobs là (Matalas và Jacobs, 1964; Vogel và Stedinger, 1985):
$$\hat{\mu}_y = \bar{y}_1 + \frac{n_2}{n_1 + n_2} \hat{\beta} \left( \bar{x}_2 – \bar{x}_1 \right) \tag{8–7}$$
và
$$\hat{\sigma}^2_y = \frac{1}{n_1 + n_2 – 1} \left[ (n_1 – 1)s^2_{y_1} + (n_2 – 1)\hat{\beta}^2 s^2_{x_2} + (n_2 – 1)\alpha^2(1 – \hat{\rho}^2)s^2_{y_1} \right.$$
$$\left. + \frac{n_1 n_2}{n_1 + n_2} \hat{\beta}^2 \left( \bar{x}_2 – \bar{x}_1 \right)^2 \right] \tag{8–8}$$
trong đó
$$\hat{\rho} = \hat{\beta} \frac{s_{x_1}}{s_{y_1}} \tag{8–9}$$
$$\hat{\beta} = \frac{\sum_{i=1}^{n_1} (x_i – \bar{x}_1)(y_i – \bar{y}_1)} {\sum_{i=1}^{n_1} (x_i – \bar{x}_1)^2} \tag{8–10}$$
và
$$\alpha^2 = \frac{n_2 (n_1 – 4)(n_1 – 1)}{(n_2 – 1)(n_1 – 3)(n_1 – 2)} \tag{8–11}$$
Điều quan trọng là cần hiểu độ chính xác của các ước lượng Matalas–Jacobs cho giá trị trung bình và phương sai của đỉnh lũ tại trạm ngắn. Sử dụng các định nghĩa ở trên, phương sai \(\mathrm{Var}(\cdot)\) của giá trị trung bình ước lượng tại trạm y được cho bởi:
$$\mathrm{Var}(\hat{\mu}_y) = \frac{\sigma_y^2}{n_1} \left[ 1 – \frac{n_2}{n_1 + n_2} \left( \rho^2 – \frac{1 – \rho^2}{n_1 – 3} \right) \right] \tag{8–12}$$
trong khi phương sai của phương sai đỉnh lũ tại trạm y là:
$$\mathrm{Var}(\hat{\sigma}^2_y) = \frac{2\sigma_y^4}{n_1 – 1} + \frac{n_2 \sigma_y^4}{(n_1 + n_2 – 1)^2 (n_1 – 3)} \left( A\rho^4 + B\rho^2 + C \right) \tag{8–13}$$
trong đó:
$$A = \frac{(n_2 + 2)(n_1 – 6)(n_1 – 8)}{(n_1 – 5)} + (n_1 – 4) \left( \frac{n_1 n_2 (n_1 – 4)}{(n_1 – 3)(n_1 – 2)} – \frac{2n_2 (n_1 – 4)}{(n_1 – 3)} – 4 \right) \tag{8–14} $$
$$B = \frac{6(n_2 + 2)(n_1 – 6)}{(n_1 – 5)} + 2(n_2^2 – n_1 – 14)$$
$$ + (n_1 – 4) \left( \frac{2n_2 (n_1 – 5)}{(n_1 – 3)} – 2(n_1 + 3) – \frac{2n_1 n_2 (n_1 – 4)}{(n_1 – 3)(n_1 – 2)} \right) \tag{8–15} $$
$$C = 2(n_1 + 1) + \frac{3(n_2 + 2)}{(n_1 – 5)} + \frac{(n_1 + 1)(2n_1 + n_2 – 2)}{(n_1 – 1)(n_1 – 3)}$$
$$+ (n_1 – 4) \left( \frac{2n_2}{(n_1 – 3)} + 2(n_1 + 1) + \frac{n_1 n_2 (n_1 – 4)}{(n_1 – 3)(n_1 – 2)} \right) \tag{8–16}$$
Các công thức này tương ứng với các phương trình trong Matalas và Jacobs (1964), IACWD (1982, phụ lục 7) và Vogel & Stedinger (1985).
Nếu cải thiện độ chính xác của ước lượng trung bình tại trạm y được mô tả bằng sự gia tăng độ dài chuỗi hiệu dụng \(n_e\), thì \(n_e\) được xác định bởi phương trình:
$$\mathrm{Var}(\hat{\mu}_y) = \frac{\sigma_y^2}{n_e + n_1} \tag{8–17}$$
trong đó \(\sigma_y^2\) là phương sai thực của chuỗi y. Vì \(\mathrm{Var}(\hat{\mu}_y)\) trong phương trình (8–12) tỉ lệ thuận với \(\sigma_y^2\), nên phương sai của chuỗi y được triệt tiêu khi tính \(n_e\). Do đó, tổng độ dài chuỗi hiệu dụng tính theo ước lượng trung bình là
$$n_e + n_1 = \frac{n_1}{ 1 – \frac{n_2}{n_1+n_2} \left( \rho^2 – \frac{1 – \rho^2}{n_1 – 3} \right) } \tag{8–18}$$
và tương ứng với phương trình 7-7 trong IACWD (1982, phụ lục 7).
Về mặt tính toán phân vị lũ, ước lượng phương sai quan trọng hơn nhiều so với ước lượng giá trị trung bình. Do đó, khi sử dụng các ước lượng Matalas–Jacobs cho phân tích tần suất lũ, vấn đề then chốt là mức gia tăng hiệu dụng về độ dài chuỗi xét theo độ chính xác của ước lượng phương sai. Sử dụng các phương trình (8–13) đến (8–16), mối quan hệ cần thiết để tính tổng độ dài chuỗi hiệu dụng cho ước lượng phương sai là:
$$(n_e + n_1) = \frac{2}{ \frac{2}{n_1 – 1} + \frac{n_2}{(n_1 + n_2 – 1)^2 (n_1 – 3)} \left( A\rho^4 + B\rho^2 + C \right) } + 1. \tag{8–19}$$
Việc sử dụng các ước lượng Matalas–Jacobs là phù hợp khi chúng mang lại cải thiện đáng kể cho cả ước lượng trung bình và phương sai của đỉnh lũ tại trạm chuỗi ngắn y, tương ứng với \(n_e\) khoảng 4 hoặc 5 năm trở lên. Điều này thường xảy ra khi \(\hat{\rho} > 0.80\) (Vogel và Stedinger, 1985).
Các phương trình trên được xây dựng với giả định rằng logarit của các quan trắc đồng thời tại trạm chuỗi ngắn \(y_i\) và tại trạm chuỗi dài \(x_i\) tuân theo phân phối normal chung với độ lệch (skewness) bằng 0. Khi giả định này bị vi phạm nghiêm trọng, các phương trình trên không còn chính xác và kỹ thuật này cần được sử dụng một cách thận trọng.
2. Mở rộng chuỗi với MOVE
Sau khi tính được các ước lượng Matalas–Jacobs cải tiến cho giá trị trung bình và phương sai tại trạm y, và độ dài chuỗi hiệu dụng \(n_1 + n_e\) tương ứng với cải thiện trong ước lượng phương sai (phương trình 8–19), bước tiếp theo là tạo ra \(n_e\) giá trị quan trắc bổ sung để thêm vào chuỗi y, nhằm đưa phần thông tin bổ sung này vào phân tích tần suất. Đây là phương pháp sử dụng ý tưởng Maintenance of Variance Extension (MOVE) do Hirsch (1982) đề xuất. Như tên gọi, các kỹ thuật này được phát triển nhằm duy trì phương sai của chuỗi y được tạo ra khi nó được mở rộng bằng một chuỗi dài hơn bổ sung, ký hiệu ở đây là x.
Theo gợi ý của Vogel và Stedinger (1985), có thể thận trọng trong việc chọn tham số mô hình sao cho các giá trị gốc và các giá trị mở rộng có giá trị trung bình và phương sai đúng với yêu cầu của nhà thủy văn. Trong trường hợp này, \(n_1\) quan trắc gốc thể hiện chính nó, và \(n_e\) giá trị bổ sung biểu thị phần thông tin do các quan trắc bổ sung trong chuỗi x cung cấp, với điều kiện tương quan chéo giữa hai chuỗi không hoàn hảo.
Cần lưu ý rằng quy trình này chỉ thêm đúng \(n_e\) giá trị quan trắc vào chuỗi y gốc và các giá trị \(n_e\) đó có chứa thông tin cần thiết để truyền tải về giá trị trung bình và phương sai tại trạm y.
Một mô hình hồi quy tuyến tính được sử dụng để mở rộng chuỗi tại trạm \(y_i\) thêm \(n_e\) năm như sau (Vogel và Stedinger, 1985):
$$\hat{y}_i = a + b (x_i – \bar{x}_e) \quad \text{với} \quad i = n_1+1, \ldots, n_1 + n_e \tag{8–20}$$
trong đó \(\bar{x}_e\) là giá trị trung bình của \(n_e\) phần tử trong chuỗi x thuộc giai đoạn không trùng với chuỗi y gốc, được dùng để mở rộng chuỗi y:
$$\bar{x}_e = \frac{1}{n_e} \sum_{i=n_1+1}^{n_1+n_e} x_i \tag{8–21}$$
và
$$s^2_{x_e} = \frac{1}{n_e – 1} \sum_{i=n_1+1}^{n_1+n_e} (x_i – \bar{x}_e)^2. \tag{8–22}$$
Hệ số chặn a dùng để tạo \(n_e\) giá trị mới được tính như sau:
$$a = \frac{(n_1 + n_e)\hat{\mu}_y – n_1 \bar{y}_1}{n_e} \tag{8–23}$$
Hệ số góc b (b > 0) được ước lượng từ:
$$b^2 = \frac{(n_1 + n_e – 1)\hat{\sigma}^2_y – (n_1 – 1)s^2_{y_1} – n_1(\bar{y}_1 – \hat{\mu}_y)^2 – n_e(a – \hat{\mu}_y)^2} {(n_e – 1)s^2_{x_e}}. \tag{8–24}$$
Nếu \(b^2\) nhỏ hơn không, điều đó cho thấy việc mở rộng hữu ích với phương pháp này là không thể thực hiện.
3. Tóm tắt quy trình
Các bước bổ sung chuỗi để ước lượng trung bình và phương sai tại trạm chuỗi ngắn và xây dựng chuỗi mở rộng với \(n_e\) quan trắc bổ sung đưa vào EMA như sau:
- Chọn trạm chuỗi dài gần và có ý nghĩa thủy văn để mở rộng trạm chuỗi ngắn cần phân tích. Tương quan chéo giữa hai trạm là yếu tố then chốt và cần càng lớn càng tốt. Đồ thị chuỗi theo thời gian của hai trạm có thể cho thấy việc truyền thông tin giữa hai trạm có hợp lý không. Trạm chuỗi dài có cung cấp góc nhìn tốt hơn về các sự kiện thủy văn trong chuỗi ngắn không?
- Phân tích thống kê và quan hệ hồi quy giữa trạm chuỗi dài và ngắn sử dụng logarit cơ số 10 của đỉnh lũ. Nếu hệ số tương quan \(\hat{\rho}\) (tính theo (8–9)) vượt ngưỡng quan trọng (\(\hat{\rho} > 0.80\)), thì có thể mở rộng chuỗi. Nếu không, có thể cần dùng phương pháp khác như dùng sai số bình phương có trọng số hoặc ước lượng khu vực.
- Ước lượng các thống kê mẫu cho chuỗi \(n_1\) năm đồng thời bằng (8–1) đến (8–6), sau đó tính trung bình và phương sai ước lượng cho trạm y dựa trên toàn bộ chuỗi của trạm chuỗi dài bằng (8–7) và (8–8).
- Tính tổng độ dài chuỗi hiệu dụng \(n_1 + n_e\) theo (8–19); \(n_e\) là số quan trắc cần bổ sung vào chuỗi y.
- Ước lượng các tham số mở rộng bằng (8–23) và (8–24). Dùng mô hình (8–20) để sinh \(n_e\) giá trị bổ sung từ \(n_2\) năm không cùng thời gian. Kiểm tra tính hợp lý của kết quả mở rộng. Ví dụ: nếu \(n_e\) năm mở rộng ngắn lại chứa các trận lũ lớn nhất trong chuỗi dài, thì hệ số lệch có thể bị sai lệch so với thực tế của chuỗi ngắn; trong trường hợp này, cần chọn \(n_e\) năm khác hợp lý hơn để phản ánh đúng hệ số lệch dự kiến.
- Có thể tiến hành phân tích tần suất bằng cách sử dụng chuỗi lưu lượng đã được mở rộng \(n_1 + n_e\).
Quy trình này gần đây được phát triển với trọng tâm vào \(n_e\) năm. Có thể cần thực hiện thêm công việc để lựa chọn các năm \(n_e\). Như đã nêu ở trên và trong Matalas và Jacobs (1964), giả định cơ bản của mô hình là phân phối Normal chung giữa hai trạm, với độ lệch bằng 0, cần được xem xét lại.
Một ví dụ được trình bày ở phần tiếp theo. Tài liệu bổ sung để thực hiện các phép tính này và ví dụ có sẵn tại:
https://acwi.gov/hydrology/Frequency/b17c/.
4. Ví dụ MOVE — Suwanee Creek tại Suwanee, Georgia
Một ví dụ về mở rộng chuỗi sử dụng MOVE được trình bày cho Suwanee Creek tại Suwanee, Georgia (USGS trạm 02334885), nơi diện tích lưu vực là 47,0 dặm vuông (mi²). Lưu vực này nằm ở miền trung-bắc Georgia như thể hiện ở Hình 8–1. Có 20 năm số liệu tại trạm 02334885 từ 1985 đến 2004, được coi là tương đối ngắn, như thể hiện ở Hình 8–2. Phân tích 20 năm số liệu của Suwanee Creek cho kết quả ước lượng thấp đối với lưu lượng lũ, chẳng hạn như lũ 0,01 AEP, so với các trạm dài hạn khác trong khu vực.
Có một trạm đo lân cận trên sông Etowah tại Canton, Georgia (USGS trạm 02392000), có 113 năm số liệu từ 1892 đến 2004 và diện tích lưu vực là 613 mi². Số liệu đỉnh lũ hàng năm của sông Etowah được dùng để mở rộng chuỗi của Suwanee Creek thêm 13 năm nhằm ước lượng lũ thiết kế như lũ 0,01 AEP.
Số liệu đỉnh lũ hàng năm đồng thời của sông Etowah và Suwanee Creek đến năm 2004 được liệt kê trong bảng 8–1. Trong 8 của 20 năm số liệu, đỉnh lũ hàng năm lớn nhất xảy ra cùng một sự kiện lũ ở cả Suwanee Creek và sông Etowah. Tuy nhiên, trong 12 của 20 năm số liệu đồng thời, đỉnh lũ hàng năm này lại tương ứng với các trận lũ khác nhau.
Trong mục đích của việc mở rộng chuỗi số liệu, đỉnh lũ đồng thời được hiểu là những đỉnh xảy ra trong cùng một năm thủy văn, chứ không nhất thiết là trong cùng một trận lũ.
Suwanee Creek tại Suwanee, Georgia, trạm USGS mã 02334885,
và sông Etowah tại Canton, Georgia, trạm USGS mã 02392000.
Bảng 8–1. Tóm tắt số liệu đỉnh lũ hàng năm quan trắc đồng thời cho sông Etowah và Suwanee Creek từ năm 1985 đến 2004.
| Năm thủy văn | Lưu lượng đỉnh hàng năm sông Etowah (ft³/s) | Lưu lượng đỉnh hàng năm Suwanee Creek (ft³/s) |
|---|---|---|
| 1985 | 5,030 | 1,440 |
| 1986 | 3,090 | 386 |
| 1987 | 12,200 | 2,150 |
| 1988 | 9,340 | 948 |
| 1989 | 9,080 | 1,220 |
| 1990 | 27,100 | 3,760 |
| 1991 | 5,940 | 1,320 |
| 1992 | 7,660 | 696 |
| 1993 | 10,900 | 2,540 |
| 1994 | 9,420 | 1,190 |
| 1995 | 10,500 | 2,650 |
| 1996 | 19,500 | 4,350 |
| 1997 | 11,300 | 2,360 |
| 1998 | 15,000 | 2,900 |
| 1999 | 5,530 | 816 |
| 2000 | 8,900 | 862 |
| 2001 | 9,270 | 2,090 |
| 2002 | 7,100 | 1,260 |
| 2003 | 13,600 | 2,940 |
| 2004 | 15,300 | 3,270 |
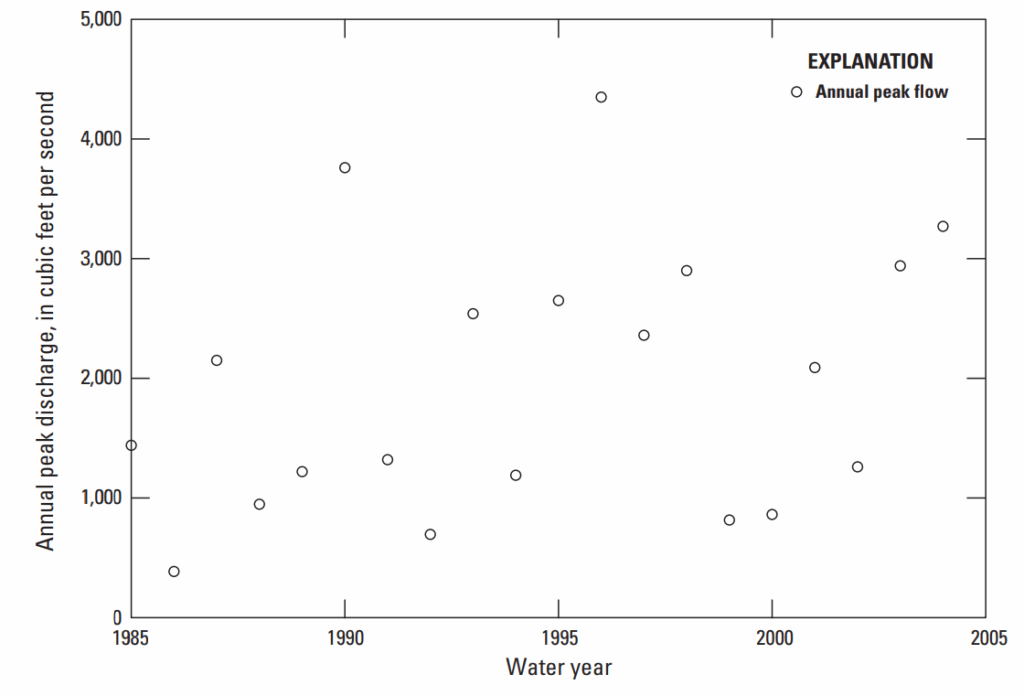
Hình 8–2. Biểu đồ thể hiện lưu lượng đỉnh hàng năm của Suwanee Creek, trạm USGS mã 02334885, trạm có chuỗi số liệu ngắn, từ năm 1985 đến 2004.
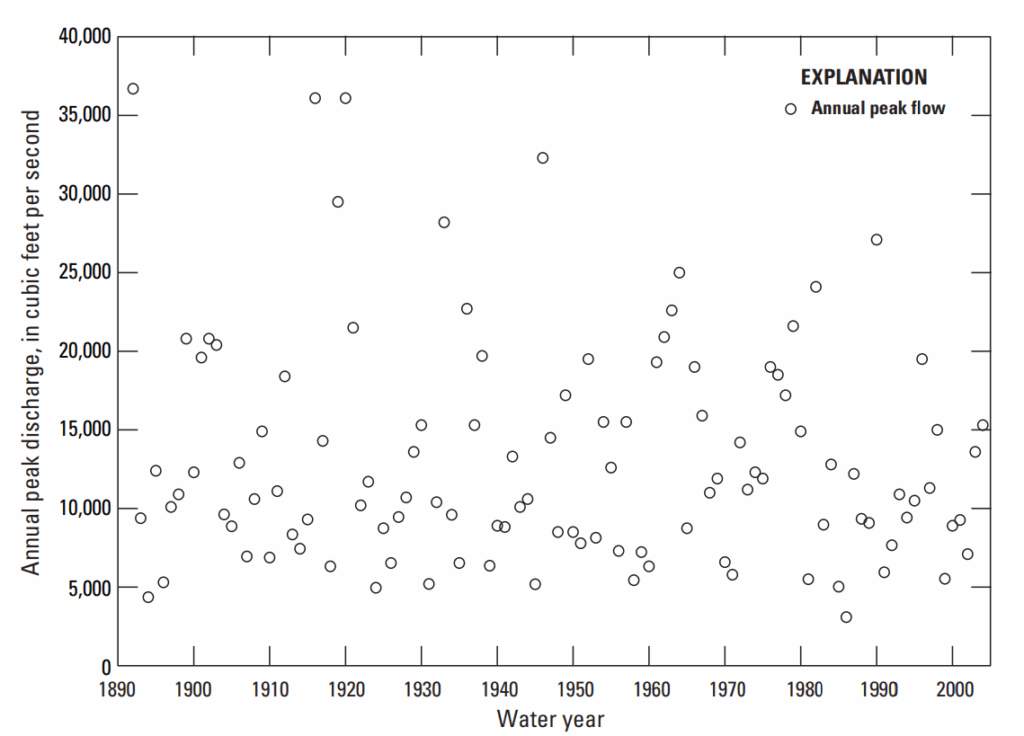
Hình 8–3. Biểu đồ thể hiện lưu lượng đỉnh hàng năm của sông Etowah, trạm USGS mã 02392000, trạm có chuỗi số liệu dài, từ năm 1892 đến 2004.
Lưu lượng đỉnh hàng năm của sông Etowah tại Canton, Georgia (trạm chuỗi dài), được thể hiện ở Hình 8–3 cho giai đoạn 1892–2004. Như thể hiện ở Hình 8–3, đã có một số trận lũ lớn được ghi nhận trên sông Etowah trước năm 1985, khi việc thu thập số liệu hệ thống tại Suwanee Creek bắt đầu. Giai đoạn thu thập số liệu hệ thống tại Suwanee Creek từ 1985 đến 2004 không bao gồm một số trận lũ lớn đã xảy ra vào các năm 1892, 1916 và 1919 tại trạm đo gần đó trên sông Etowah. Những trận lũ lớn này, cùng với thông tin từ các sự kiện trong giai đoạn 1892–1984, có thể được sử dụng thông qua phương pháp bổ sung chuỗi để cải thiện ước lượng trung bình và phương sai, cũng như mở rộng chuỗi lũ tại Suwanee Creek.
20 năm số liệu đồng thời của Suwanee Creek và sông Etowah được thể hiện ở Hình 8–4 theo thang log-log. Như thể hiện ở Hình 8–4, logarit của lưu lượng đỉnh hàng năm xác lập một quan hệ tuyến tính với giá trị \(R^2\) bằng 0,7258. Hệ số tương quan là 0,8519, lớn hơn giá trị ngưỡng (\(\hat{\rho} > 0.80\)) cho cả trung bình và phương sai. Điều này cho thấy giá trị trung bình và độ lệch chuẩn từ chuỗi mở rộng sẽ được cải thiện nếu sử dụng chuỗi dài hơn. Mặc dù sông Etowah lớn hơn nhiều so với Suwanee Creek, nhưng có mối tương quan mạnh giữa lưu lượng đỉnh hàng năm, điều này tạo điều kiện cho việc mở rộng chuỗi. Quan hệ tuyến tính trong Hình 8–4 là đường hồi quy bình phương tối thiểu thông thường được tính bằng logarit của dữ liệu.
Chuỗi 20 năm của Suwanee Creek từ 1985 đến 2004 cho kết quả ước lượng thấp về lưu lượng lũ, như lũ có xác suất vượt 0,01 hằng năm, vì các trận lũ lớn trước khi có thu thập số liệu hệ thống không được xét trong phân tích tần suất. Giai đoạn 1985–2004 là thời kỳ tương đối khô hạn so với giai đoạn trước 1985, như thể hiện qua chuỗi dài hạn của sông Etowah ở Hình 8–3.
Chuỗi số liệu lũ của Suwanee Creek đã được mở rộng bằng phương pháp bổ sung chuỗi cho giá trị trung bình và phương sai, và MOVE, dựa trên dữ liệu lưu lượng đỉnh hàng năm của sông Etowah từ 1892–1984 và giai đoạn trùng nhau từ 1985–2004. Như thể hiện ở Hình 8–4, có mối quan hệ tuyến tính mạnh giữa logarit của lưu lượng đỉnh hàng năm. Hệ số tương quan ước lượng cho giai đoạn trùng nhau 1985–2004 là 0,8519.
Các đại lượng thống kê của chuỗi quan trắc là:
- \(y_i\) = lưu lượng theo logarit cho Suwanee Creek tại năm i
- \(x_i\) = lưu lượng theo logarit cho sông Etowah tại năm i
- \(n_1\) = giai đoạn số liệu đồng thời hoặc trùng nhau, 20 năm (1985–2004)
- \(n_2\) = giai đoạn số liệu không đồng thời, 93 năm (1892–1984)
- \(\bar{y}_1\) = giá trị trung bình logarit cho Suwanee Creek trong giai đoạn đồng thời = 3,215 log units
- \(\bar{x}_1\) = giá trị trung bình logarit cho sông Etowah trong giai đoạn đồng thời = 3,984 log units
- \(\bar{x}_2\) = giá trị trung bình logarit cho sông Etowah trong giai đoạn không đồng thời = 4,079 log units
- \(s_{y_1}\) = độ lệch chuẩn logarit cho Suwanee Creek trong giai đoạn đồng thời = 0,279 log units
- \(s_{x_1}\) = độ lệch chuẩn logarit cho sông Etowah trong giai đoạn đồng thời = 0,214 log units
- \(s_{x_2}\) = độ lệch chuẩn logarit cho sông Etowah trong giai đoạn không đồng thời = 0,219 log units
Từ phương trình (8–19), độ dài chuỗi mở rộng ước lượng \(n_e\) là 13 năm.
Chuỗi \(n_e\) năm mở rộng của \(y_i\) cho Suwanee Creek được ước lượng bằng cách sử dụng 13 năm gần nhất của giai đoạn không trùng (1972–1984). Dùng các phương trình Matalas–Jacobs (8–7) đến (8–11), trung bình và phương sai đã bổ sung lần lượt là: \(\mu_y = 3,3024 \quad \text{và} \quad \sigma_y^2 = 0,08105\)
Giải các phương trình (8–20) đến (8–24), phương trình MOVE ở dạng tuyến tính logarit dùng để tạo chuỗi \(n_e\) lưu lượng là:
$$y_i = 3,4364 + 1,4416 \,(x_i – 4,1414) \tag{8–25}$$
trong đó \(x_i\) là logarit cơ số 10 của lưu lượng sông Etowah cho giai đoạn 1972–1984.
và:
$$Q_i = 10^{y_i} \tag{8–26}$$
trong đó \(Q_i\) là lưu lượng mở rộng (đơn vị ft³/s) cho Suwanee Creek.
Phương trình 8–26 được sử dụng để ước lượng lưu lượng đỉnh hàng năm cho Suwanee Creek trong giai đoạn 1972–1984, qua đó mở rộng chuỗi thêm 13 năm bằng dữ liệu từ sông Etowah.
Các ước lượng lưu lượng mở rộng cho Suwanee Creek được liệt kê trong bảng 8–2.
Các ước lượng lưu lượng gốc từ trạm chuỗi dài (sông Etowah) được liệt kê trong bảng 8–3.
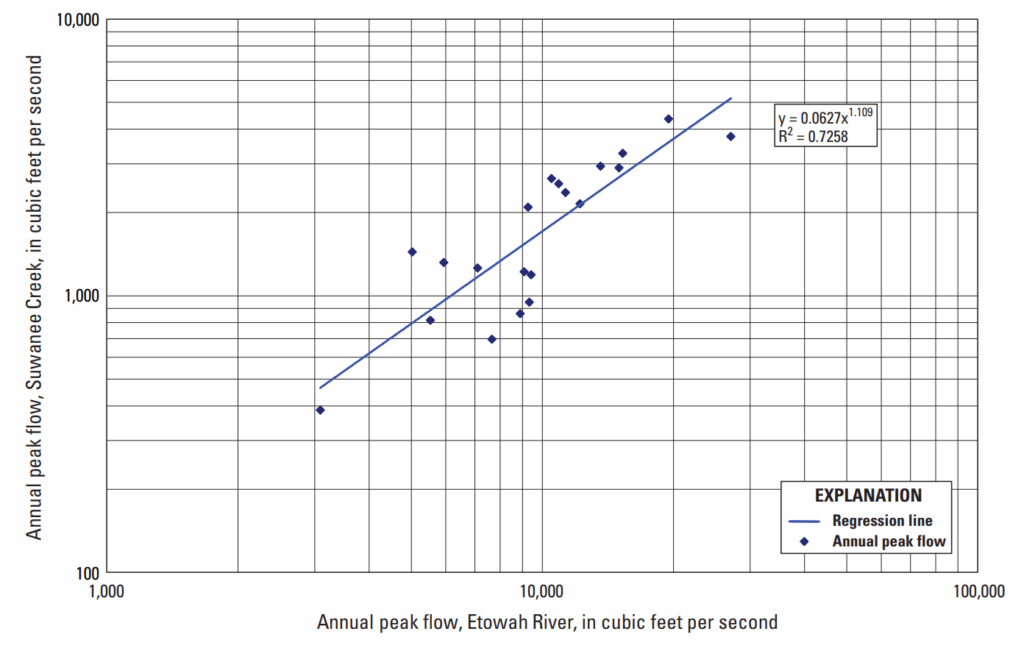
Hình 8–4. Biểu đồ 20 năm số liệu đồng thời của Suwanee Creek và sông Etowah trong giai đoạn 1985–2004, kèm theo đường hồi quy bình phương tối thiểu thông thường.
Bảng 8–2. Chuỗi mở rộng bằng phương pháp MOVE trong 13 năm (1972 đến 1984) cho Suwanee Creek tại Suwanee, Georgia (trạm 02334885).
| Năm thủy văn | Lưu lượng đỉnh hàng năm (ft³/s) |
|---|---|
| 1972 | 2,830 |
| 1973 | 2,010 |
| 1974 | 2,300 |
| 1975 | 2,200 |
| 1976 | 4,310 |
| 1977 | 4,150 |
| 1978 | 3,730 |
| 1979 | 5,180 |
| 1980 | 3,040 |
| 1981 | 722 |
| 1982 | 6,070 |
| 1983 | 1,460 |
| 1984 | 2,440 |
Bảng 8–3. Ghi nhận lũ trong 93 năm (1892 đến 1984) cho sông Etowah tại Canton, Georgia (trạm 02335000).
| Năm thủy văn | Lưu lượng đỉnh hàng năm (ft³/s) | Năm thủy văn | Lưu lượng đỉnh hàng năm (ft³/s) | Năm thủy văn | Lưu lượng đỉnh hàng năm (ft³/s) | Năm thủy văn | Lưu lượng đỉnh hàng năm (ft³/s) |
|---|---|---|---|---|---|---|---|
| 1892 | 36,700 | 1923 | 11,700 | 1954 | 15,500 | 1969 | 11,900 |
| 1893 | 9,380 | 1924 | 4,960 | 1955 | 12,600 | 1970 | 6,590 |
| 1894 | 4,360 | 1925 | 8,740 | 1956 | 7,300 | 1971 | 5,790 |
| 1895 | 12,400 | 1926 | 6,530 | 1957 | 15,500 | 1972 | 14,200 |
| 1896 | 5,300 | 1927 | 9,460 | 1958 | 5,440 | 1973 | 11,200 |
| 1897 | 14,000 | 1928 | 10,700 | 1959 | 7,230 | 1974 | 12,300 |
| 1898 | 10,900 | 1929 | 13,600 | 1960 | 6,320 | 1975 | 11,900 |
| 1899 | 20,800 | 1930 | 15,300 | 1961 | 19,300 | 1976 | 19,000 |
| 1900 | 12,300 | 1931 | 5,200 | 1962 | 20,900 | 1977 | 18,500 |
| 1901 | 19,600 | 1932 | 11,700 | 1963 | 22,600 | 1978 | 17,200 |
| 1902 | 20,800 | 1933 | 28,200 | 1964 | 25,000 | 1979 | 21,600 |
| 1903 | 20,200 | 1934 | 9,060 | 1965 | 8,740 | 1980 | 14,900 |
| 1904 | 8,870 | 1935 | 6,530 | 1966 | 19,000 | 1981 | 5,500 |
| 1905 | 8,870 | 1936 | 22,700 | 1967 | 15,900 | 1982 | 24,100 |
| 1906 | 12,900 | 1937 | 15,300 | 1968 | 11,000 | 1983 | 8,970 |
| 1907 | 6,950 | 1938 | 19,700 | 1984 | 12,800 | ||
| 1908 | 10,600 | 1939 | 6,360 | ||||
| 1909 | 14,900 | 1940 | 8,900 | ||||
| 1910 | 6,880 | 1941 | 8,820 | ||||
| 1911 | 11,100 | 1942 | 13,300 | ||||
| 1912 | 18,400 | 1943 | 10,100 | ||||
| 1913 | 8,350 | 1944 | 10,600 | ||||
| 1914 | 7,440 | 1945 | 5,180 | ||||
| 1915 | 9,300 | 1946 | 32,300 | ||||
| 1916 | 36,100 | 1947 | 14,500 | ||||
| 1917 | 14,300 | 1948 | 8,500 | ||||
| 1918 | 6,320 | 1949 | 17,200 | ||||
| 1919 | 29,500 | 1950 | 8,500 | ||||
| 1920 | 36,100 | 1951 | 7,790 | ||||
| 1921 | 21,500 | 1952 | 19,500 | ||||
| 1922 | 10,200 | 1953 | 8,140 |
Hỗ trợ duy trì trang:
Tôi xây dựng trang này để chia sẻ các tài liệu kỹ thuật cốt lõi trong thiết kế hạ tầng giao thông.
Nếu bạn thấy nội dung hữu ích và muốn góp phần duy trì trang hoạt động bền vững, tôi rất trân trọng mọi sự ủng hộ.